
锁优化
文章已同步至GitHub开源项目: JVM底层原理解析
高效并发是JDK5升级到JDK6后一项重要的改进,HotSpot虚拟机开发团队在这个版本上花费了巨大的资源去实现各种锁优化。比如,自旋锁,自适应自旋锁,锁消除,锁膨胀,轻量级锁,偏向锁等。这些技术都是为了在线程之间更高效的共享数据及解决竞争问题。从而提高程序的运行效率。
自旋锁和自适应自旋锁
-
自旋锁
在互斥同步的时候,对性能影响最大的就是阻塞的实现,挂起线程,恢复线程等的操作都需要用户态转为内核态去完成。这些操作给性能带来了巨大的压力。
虚拟机的开发团队也注意到,共享数据的锁定状态只会持续很短的时间。为了这很短的时间让线程挂起,然后转为内核态的时间可能比锁定状态的时间更长。所以,我们可以让等待同步锁的进程不要进入阻塞,而是在原地稍微等待一会儿,不要放弃处理器的执行时间,看看持有锁的线程是不是很快就会释放锁。为了让线程等待,我们可以让线程执行一个忙循环(原地自旋),这就是自旋锁。
自旋锁在JDK1.4.2之后就已经引入,但是默认是关闭的。我们可以使用-XX:+UseSpinning参数来开启。在JDK1.6之后就默认开启了。自旋锁并不是阻塞,所以它避免了用户态到内核态的频繁转化,但是它是要占用处理器的执行时间的。
如果占有对象锁的线程在很短的时间内就执行完,然后释放锁,这样的话,自旋锁的效果就会非常好。
如果占有对象锁的线程执行时间很长,那么自旋锁会白白消耗处理器的执行时间,这就带来了性能的浪费。这样的话,还不如将等待的线程进行阻塞。默认的自旋次数是10,也就是说,如果一个线程自旋10次之后,还没有拿到对象锁,那么就会进行阻塞。
我们也可以使用参数-XX:PreBlockSpin来更改。
-
自适应自旋锁
无论是使用默认的10次,还是用户自定义的次数,对整个虚拟机来说所有的线程都是一样的。但是同一个虚拟机中线程的状态并不是一样的,有的锁对象长一点,有的短一点,所以,在JDK1.6的时候,引入了
自适应自旋锁。 自适应自旋锁意味着自旋的时间不在固定了,而是根据当前的情况动态设置。
主要取决于
同一个锁上一次的自旋时间和锁的拥有者的状态。 如果在同一个对象锁上,上一个获取这个对象锁的线程在自旋等待成功了,没有进入阻塞状态,说明这个对象锁的线程执行时间会很短,虚拟机认为这次也有可能再次成功,进而允许此次自旋时间可以更长一点。
如果对于某个锁,自旋状态下很少获得过锁,说明这个对象锁的线程执行时间相对会长一点,那么以后虚拟机可能会直接省略掉自旋的过程。避免浪费处理器资源。
自适应自旋锁的加入,随着程序运行时间的增长以及性能监控系统信息的不断完善,虚拟机对程序的自旋时间预测越来越准确,也就是
虚拟机越来越聪明了。
锁消除
锁消除指的是,在即时编译器运行的时候,代码中要求某一段代码块进行互斥同步,但是虚拟机检测到不需要进行互斥同步,因为没有共享数据,此时,虚拟机会进行优化,将互斥同步消除。
锁消除的主要判定依据来源于逃逸分析的数据支持。具体来说,如果虚拟机判断到,在一段代码中,创建的对象不会逃逸出去到其他线程,那么就可以把他当作栈上数据对待,同步也就没有必要了。
但是,大家肯定有疑问,变量是否逃逸,写代码的程序员应该比虚拟机清楚,该不该加同步互斥程序员很自信。还要让虚拟机通过复杂的过程间分析吗,这个问题的答案是:
有许多互斥同步的要求并不是程序员自己加入的,互斥同步的代码在Java中出现的程度很频繁。
我们来举一个例子。
public String concat(String s1, String s2){
return s1 + s2;
}
上边的代码很简单,将两个字符串连接,然后返回,不涉及到任何互斥同步的要求。
但是,我们来编译它
0 new #2 <java/lang/StringBuilder>
3 dup
4 invokespecial #3 <java/lang/StringBuilder.<init> : ()V>
7 aload_1
8 invokevirtual #4 <java/lang/StringBuilder.append : (Ljava/lang/String;)Ljava/lang/StringBuilder;>
11 aload_2
12 invokevirtual #4 <java/lang/StringBuilder.append : (Ljava/lang/String;)Ljava/lang/StringBuilder;>
15 invokevirtual #5 <java/lang/StringBuilder.toString : ()Ljava/lang/String;>
18 areturn
会发现,字节码中出现了StringBuilder的拼接操作。因为字符串是不可变的,在编译阶段会对String的连接自动优化。也就是用StringBuilder来连接。我们都知道,这个类是线程安全的,也就是说StringBuilder的拼接操作是需要互斥同步的条件的。此时,代码流程可能是以下这样的
public String concat(String s1, String s2){
StringBuilder sb = new StringBuilder();
sb.append(s1);
sb.append(s2);
return sb.toString();
}
此时,代码会有互斥同步,锁住sb这个对象。这样的话,就会出现程序员没有加入互斥同步条件,但字节码中以及有了。
这个时候,锁消除就发挥作用了,通过虚拟机的逃逸分析,发现sb这个对象不会逃逸出去,别的线程绝对不会访问到它,sb的动态作用域就在此方法中,此时,锁消除就会将这里的互斥同步进行消除。
运行的时候,就会忽略到同步措施直接执行。
锁粗化
原则上,我们编写代码的时候,总是推荐将同步代码块的作用范围尽可能的缩小,只有共享数据的地方同步即可。这样是为了使得同步的操作变少,等待锁的线程能尽快的拿到锁。
但是,如果一段代码中自始至终都锁的是同一个对象,那么就会对这个对象进行重复的加锁,释放,加锁,释放。频繁的进行用户态和内核态的切换,效率居然变低了。
上边的代码就是这种情况,每一次的append操作都对sb进行加锁释放,加锁释放,如果虚拟机探测到有一串零碎的操作对一个对象重复的加锁,释放,此时,虚拟机就会把加锁同步的范围粗化到整个操作的最外层。以上边的代码为例,虚拟机扩展到第一个append到最后一个append。这样的话,只需要加锁释放一次即可。
轻量级锁
轻量级锁是JDK1.6之后加入的新型锁机制,轻量级是相对应于操作系统互斥量来实现的传统锁而言的。因此,传统锁就被称之为重量级锁。但是,要注意,轻量级并不是用来代替重量级的,它设计的初衷是在没有多线程竞争的前提下,减少传统的重量级锁带来的性能消耗问题的。
首先,要理解轻量级锁以及后边的偏向锁,必须要先知道,HotSpot中对象的内存布局。对象的内存布局分为三部分,一部分是对象头(Mark Word),一部分是实例数据,还有一部分对其填充,为了让对象的大小为8字节的整数倍。
对象头中包括两部分的数据包括,对象的哈希码,GC分代年龄,锁状态等。 如果对象是数组,那么还会有额外的一部分存储数组长度。
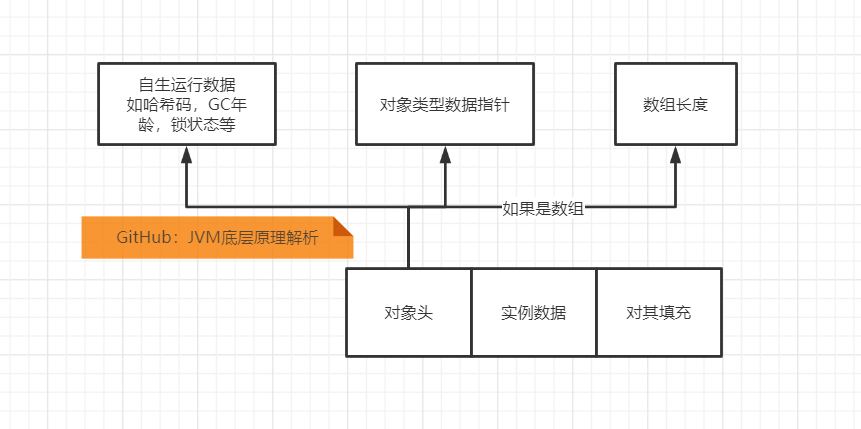
这些内容在第二章运行时数据区中的对象的实例化内存布局与访问定位+直接内存 我们已经说过了。不再赘述,此处我们只针对锁的角度进一步细化。
由于对象头中存储的信息是与对象自身定义数据无关的额外存储成本,所以为了节约效率,他被设计为一个动态的数据结构。会根据对象的状态复用自己的存储空间。具体来说,会根据当前锁状态给每一部分的值赋予不同的意义。
在32位操作系统下的HotSpot虚拟机中对象头占用32个字节,64位占用64个字节。
我们以32位操作系统来演示。以下是不同锁状态的情况下,各个部分数据的含义。
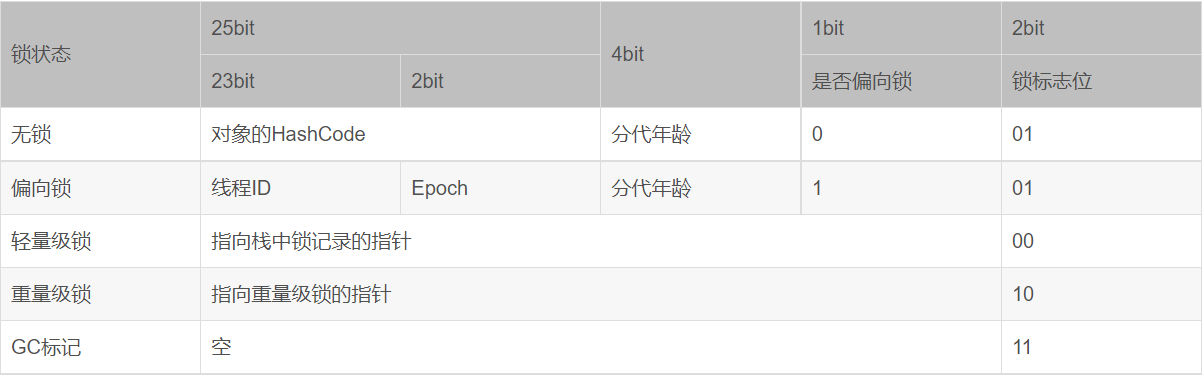
接下来我们就可以介绍轻量级锁的工作过程了。
加锁过程
-
在代码即将进入同步块的时候,虚拟机就会在当前栈帧中建立一个名为锁记录(Lock Record)的空间。然后将堆中对象的对象头拷贝到
锁记录(官方给它加了Displaced前缀)便于修改对象头的引用时存储之前的信息。此时线程栈和对象头的情况如下: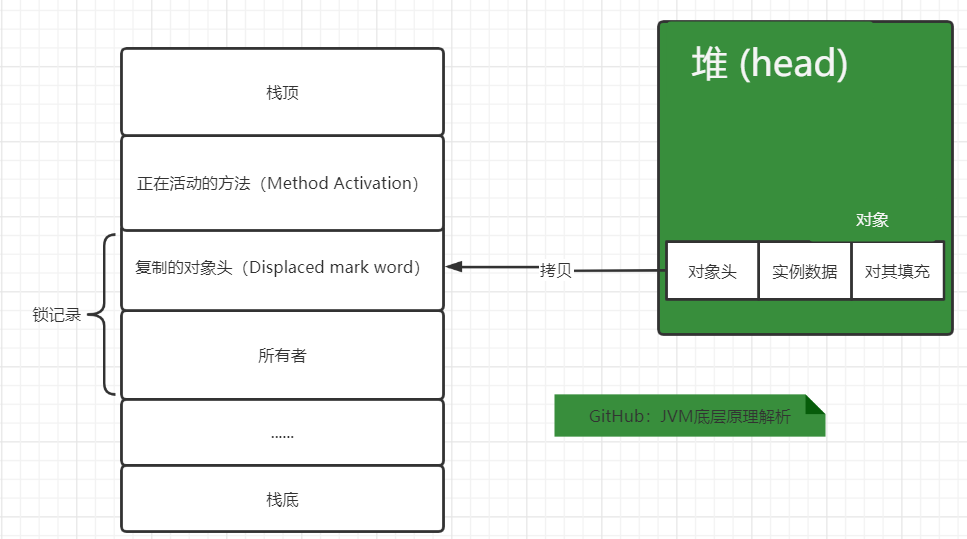
-
然后,虚拟机将使用
CAS(原子)操作尝试把堆中对象的对象头中前30个字节更新为指向锁记录的引用。-
如果成功,代表当前线程已经拥有了该对象的对象锁。然后将堆中对象头的锁标志位改为
00。此时,代表对象就处于轻量级锁定状态。状态如下所示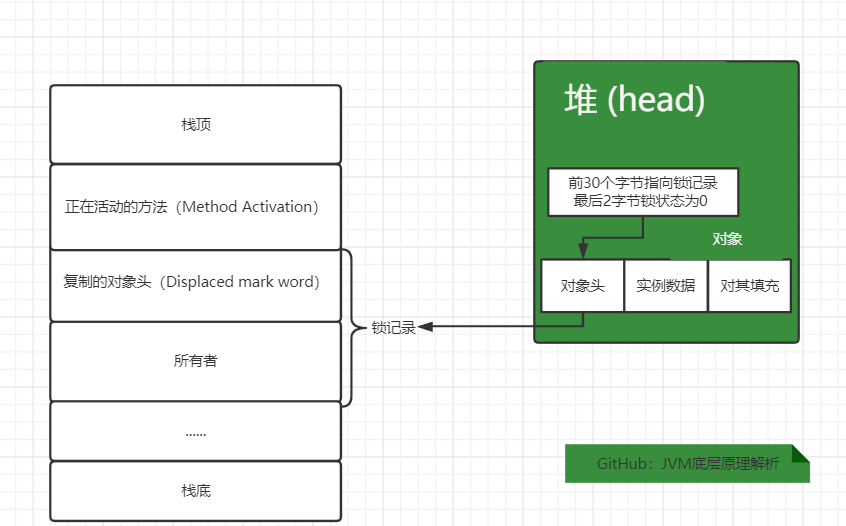
-
如果失败,也就是堆中对象头的锁状态已经是0,则意味着对象的对象锁别拿走了。
- 虚拟机会判断对象的前30个字节是不是指向当前线程
- 如果是,说明当前线程已经拿到了对象锁,可以直
接执行同步代码块。 - 如果不是,说明对象锁被其他线程拿走了,必须等待。也就是进入
自旋模式,如果在自旋一定次数后仍为获得锁,那么轻量级锁将会膨胀成重量级锁。
- 如果是,说明当前线程已经拿到了对象锁,可以直
- 如果发现有两条以上线程争用同一个对象锁,那么轻量级锁就不在有效,必须
膨胀为重量锁,将对象的锁状态改为10。此时,堆中对象的对象头前30个字节的引用就是指向重量级锁。
- 虚拟机会判断对象的前30个字节是不是指向当前线程
-
解锁过程
如果堆中对象头的前30个字节指向当前线程,说明当前线程拥有对象锁,就用CAS操作将加锁的时候复制到栈帧锁记录中的对象头替换到堆中对象的对象头。并将堆中对象头的锁状态改为01。
- 如果替换成功,说明
解锁完成。 - 如果发现有别的线程尝试过获取堆中对象的对象锁,就要在释放锁的同时,唤醒被阻塞的线程。
后言
轻量级锁提升性能的依据是:绝大多数的锁在整个同步过程中都是不存在竞争的。这样的话,就通过CAS操作避免了使用操作系统中互斥量的开销。
如果确实存在多个线程的锁竞争,除了互斥量本身的开销之外,还额外发生了CAS操作的开销。因此,在有竞争的情况下,轻量级锁会比传统的重量级锁更慢。
偏向锁
偏向锁也是JDK1.6之后引入的特性,他的目的是消除数据在无竞争状态下的同步原语,进一步提高程序的运行速度。
轻量级锁是在无竞争的情况下利用CAS原子操作来消除操作系统的互斥量,偏向锁就是在无竞争的情况下把整个同步都消除。
偏向锁的偏就是偏心的偏,他的意思是 这个锁会偏向于第一个获得它的线程。如果在接下来的执行过程中,该锁一直没有被其他线程获取,那么持有偏向锁的线程就不需要在同步,直接执行。
假设当前虚拟机开启了偏向锁(1.6之后默认开启),当锁对象第一次被线程获取的时候,虚拟机会将对象头中最后2字节的锁标志位的值不做设置,依旧是01,将倒数第三个字节偏向模式设置为01。也就是开启偏向模式。同时使用CAS原子操作将获取到这个对象锁的线程记录在对象头中。如果操作成功,那么以后持有偏向锁的线程每次进入同步代码块时,虚拟机都不会在进行同步操作。
一旦出现别的线程去获取这个锁的情况,偏向模式立马结束。根据锁对象目前是否被锁定来决定是否撤销偏向,撤销后锁标志位恢复到未锁定状态(01)或轻量级锁定(00)。后续的操作就按照轻量级锁去执行。
偏向锁,轻量级锁的状态转化如下:
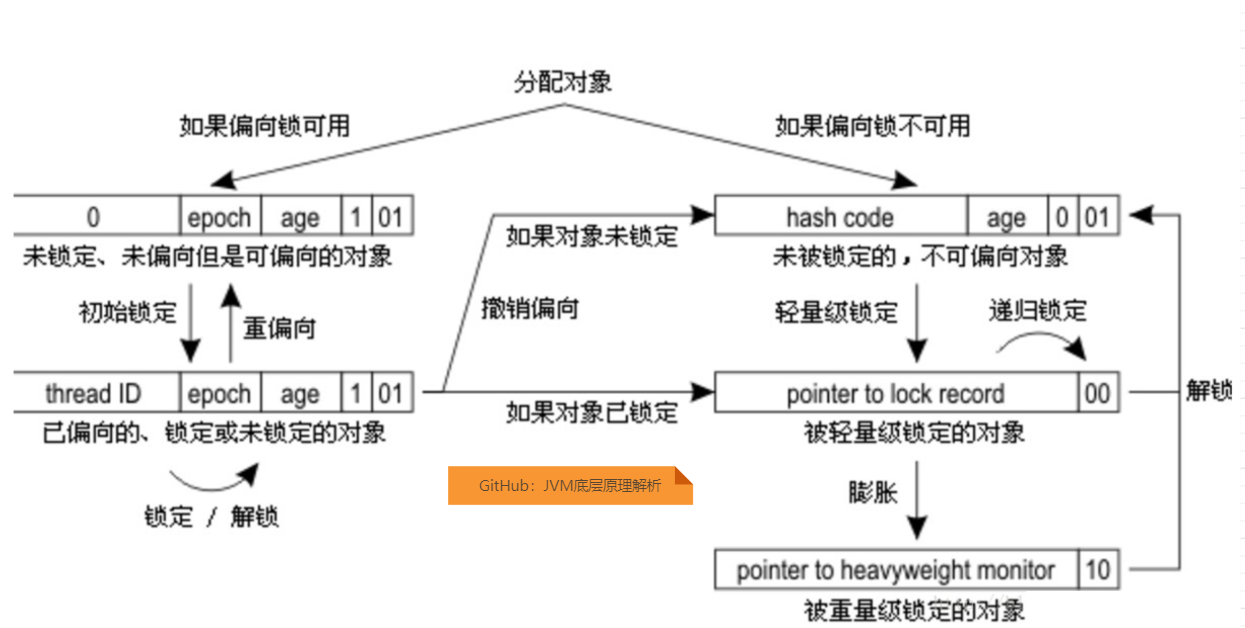
问题:
之前的轻量级锁加锁的时候,会将对象的hash码,分代年龄等数据拷贝出来,便于使用。但是,我们发现,偏向锁的过程中并未拷贝,此时,如果要使用原来对象头的数据,怎么办?
虚拟机的实现也考虑到了这个问题。
对象的哈希码并不是创建对象的时候计算的,而是第一次使用的时候,计算的。比如下边String的hash方法源码
/**
演示hash的计算时间
作者:写Bug的小杜 【[email protected]】
*/
public int hashCode() {
int h = hash;
//如果之前没有算过,则调用的时候才进行计算。否则直接返回
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
如果一个对象计算过哈希码,那么不管调用多少次,它的哈希值都应该是一样的。
当一个对象计算过hash码的时候,说明这个对象的哈希码要被用,那么,这个对象就无法进入偏向锁状态。
如果虚拟机收到一个正在偏向锁的对象的哈希码计算请求,就会立即停止偏向锁模式,膨胀为重量级锁。就会在重量级锁的栈帧中拷贝的锁状态位置中存储对象的运行时数据结构。
后言
偏向锁可以提高带有同步但是无竞争的程序性能,但是它同样是一个带有权衡效益的优化。如果程序中大多数的锁总是被不同的线程访问,那么偏向模式就是多余的。具体问题分析之后,我们可以使用参数-XX:-UseBiasedLocking来禁止使用偏向锁优化从而提高程序的运行速度。需要 具体问题,具体分析。
文章已同步至GitHub开源项目: JVM底层原理解析

